- Exploring the panes
- Selecting elements
- Setting data fields
- Letting it do the work
- For real: Mendeley
Exploring the panes
Open the demonstrator page in a new tab/window.
The page has four panes. The large central pane shows a web page. The top pane has a selector, which allows you to swop between the pages viewed in the main pane. In scenario 1 this would correspond to different pages that Jane visited on different occasions. In scenario 2 this would correspond to the example resources bookmarked by Jules. There are three different pages in the drop-down all from the same web site.
The left-hand pane shows data fields needing to be filled. In scenarios 1 and 2 this would be bibliographic entries. The example here is more like scenario 3 being a specialised web page. It was chosen as it has lots of challenging (read difficult) features ... and it is Tiree! However, the operation is the same whatever kind of page is being examined.

The bottom pane is for the currently selected element in the main pane. Initially it is empty, but click any element on the page and see what happens.
next: Selecting elements
Selecting elements and the selection pane
In the screenshot below, the title "An Cladh Beag or Cladh Beag Chòrnaig" has been selected.
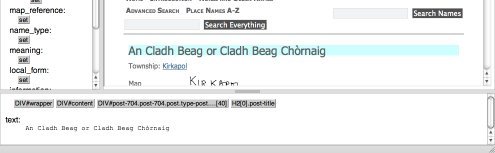
Note that the bottom pane now shows the text of the title and also a set of breadcrumb buttons representing the path to the element in the HTML DOM, similar to the ''Inspect Element" display found in many web browsers. This information might not be shown in the simple version described in scenario 1, but might be included if the user needs to have finer control over the extraction of values from the web page as in scenario 2 and scenario 3 .
As well as showing the current selection, this lower pane can be used to fine tune the slection. Clicking one of the DOM path breadcrumb changes the selection correspondingly. Try clicking "DIV#content".
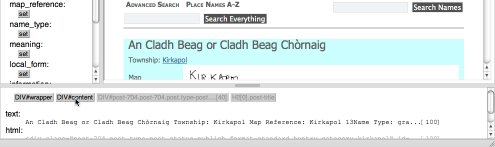
The screenshot above, show what happens after clicking the"DIV#content" breadcrumb button. Note that both the text and the highlighted area in the main pane have changed to correspond to the wider context.
Click "H2[0].post-title" to return the selection to just the title.
next: Setting data fields
Setting data fields
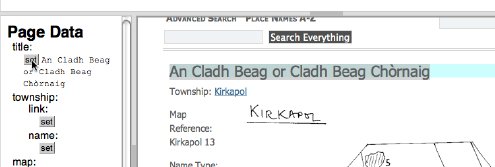
On the data pane, note that the 'set' buttons are now enabled. Click the 'set' button next to "title" and the currently selected text "An Cladh Beag or Cladh Beag Chòrnaig" is copied into the title field. (However, in addition, behind the scenes, it is also recording the full path, not just the value.)
If the selected text is also a link, then the information pane at the bottom also shows the url from the href attribute of the <a> tag.
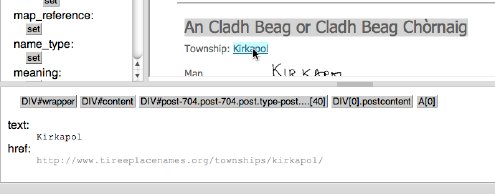
Clicking the href makes this url, rather than the text, as the focus element.
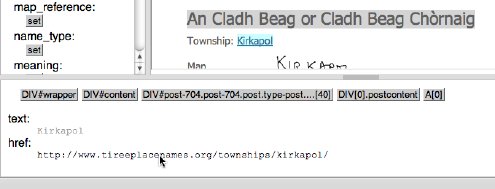
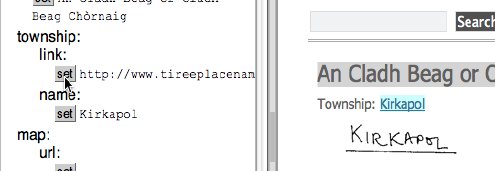
If you then click 'set' for any field (e.g. township link), this url gets copied into the field rather than the text.
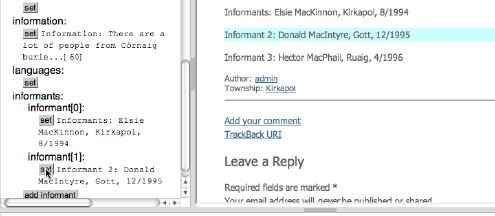
Fill in more of the fields. Here the repeating 'informants' field is being completed.
next: Letting it do the work
Letting it do the work
Now the fun bit :-)
Use the selector at the top and switch to a different page ...
... and note that the title field and many of the other fields have been pre-filled - magic!
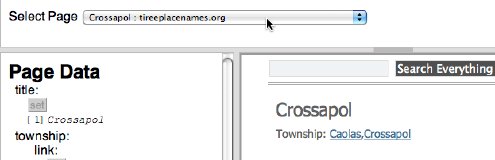
The system has used the selections from the first page to work out which areas of the new web page refer to corresponding fields.
Note that currently the protoype only generalises the top-level fields (e.g. not the township sub-fields). This is not an intrinsic issue, and dealing with sub-fields is just 'more of the same'.
However, a little more complicated are repeating fields (like the informants field). These are also not pe-filled in this demo. Dealing with multiple repeating fields is a bit like generalising from page to page, but slightly different
next: For real: Mendeley
For real: Mendeley
Of course, all very well applying this to Tiree place names, but what about real bibliographic resources?
The second demo has a number of Mendeley pages listed. The data fields on the left-hand pane are teken directly from the Aspire bookmarklet entry form (see schema specification below). Complete the entries: paper title, journal title, volume number, issue, date. Repeating fields are not implemented yet, so ignore the author fields, and you cannot at present split the page number range, simply put that in as page start or page end, whichever you prefer.
Then go to the second, third pages - magic - all filled in for you. A Mendeley recogniser created entirely as a by product of your first completion of the form :-)
In case you are wondering, the schema below, the bare Aspire field values, are all that demo2 is given; it knows nothing about the specifics of Mendeley pages whatsoever.
schema.article = {
"Title": {
"type": "text"
},
"Authors": {
"repeats": "Author",
"parts": {
"first name": "text",
"surname": "text"
}
},
"Date": {
"type": "text"
},
"DOI": {
"type": "text"
},
"Volume": {
"type": "text"
},
"Issue": {
"type": "text"
},
"Page start": {
"type": "text"
},
"Page end": {
"type": "text"
},
"Journal": {
"type": "text"
},
"ISSN": {
"type": "text"
}
};